
We’ve been using Jenkins at DesignHammer for three years with a lot of success. Our initial implementation was built by Kosta Harlan and detailed in his posts about automated migration and testing with CaperJS.
We’ve used this implementation to run a nightly content import and test suite for one of our clients. The tests include approximately 50 individual checks which analyze thousands of nodes and entities in Drupal. This build process has done a great job to ensure that data migrated to the public website is correct and consistent.
Since that time I’ve been the primary developer working with our Jenkins implementation and we’ve made several improvements in the last few years.
Making it more resilient
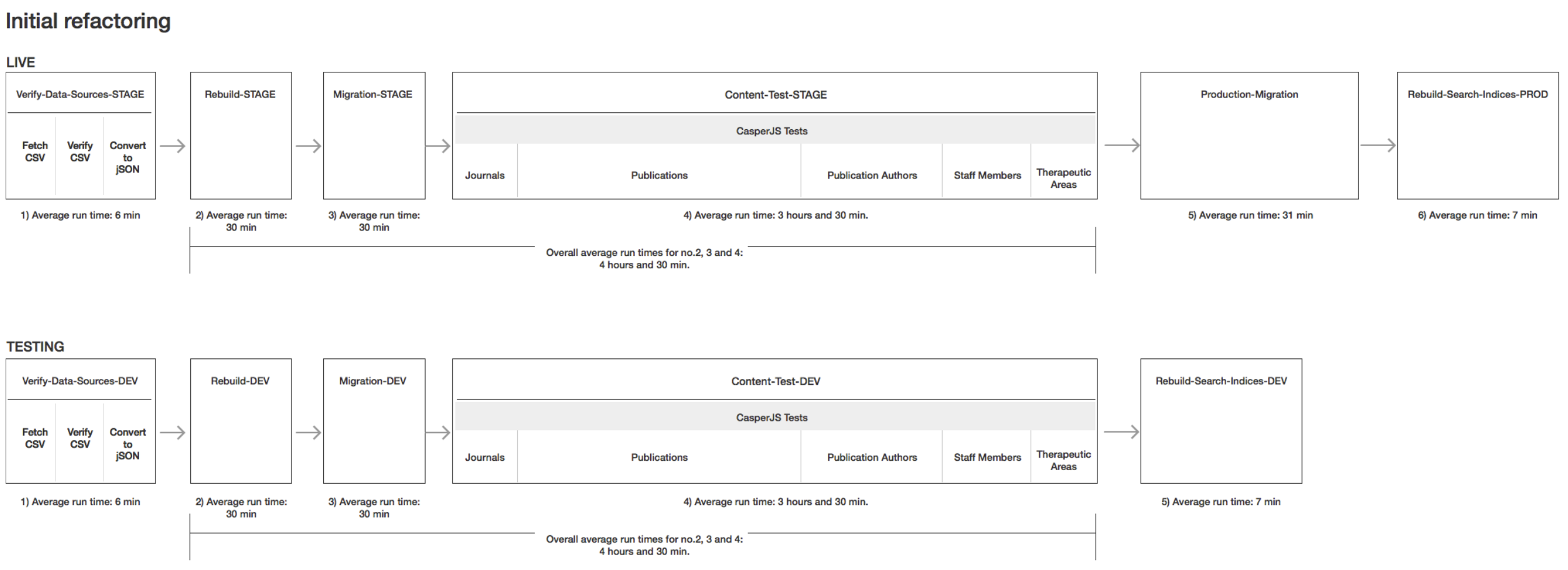
The original build process existed as a single set of Jenkins jobs configured to run in sequence on a nightly basis. It included steps for importing data from a third party system, making a clone of the the production website, migrating the new data into the clone, and then running our extensive test suite against that content before running the same migration on the production website.
If a content error was discovered during one of the test jobs, the build would fail and the next day someone could troubleshoot the issue, potentially by running a manual build during the day.

While generally successful, this approach had some limitations.
First, it was monolithic. Making any changes to the site’s codebase or the job configuration risked causing the nightly build to fail. If there was new content that needed to be present on the public site this would result in an emergency situation and unnecessary stress.
Second, the process was very lengthy (~5 hours) and was increasing steadily as new content was added to the site. Having a long process limited our ability to iterate on site changes. A manually run build would have to be started early in the day to have a chance of completing during normal business hours. There really wasn’t a meaningful test cycle.
Finally, we ran into many cases where unexpected issues would cause the build to fail and we didn’t have a good way to troubleshoot after the fact, particularly when the issues were transient. Most of these were various types of connectivity problems between the Jenkins server, the web server, and the git host. We needed better error reporting for these cases.
Testing build process
The first order of business was to make it possible to test changes to the codebase and the build process itself without risking breaking the nightly production build.
I started by preparing a new test environment on the web server to go along with stage and prod. This environment is a full instance of the Drupal website with it’s own webroot, files, and database.
We then duplicated most of the jobs in the build process but pointed them at the test environment and the dev branch in the git repo. We also removed the final prod migration.
This gave us the ability to push code changes and run the full build process in an environment that was completely separate from the nightly build. With that in place we were able to make more dramatic changes.
Making it faster
With the testing process in place I started work on speeding it up.
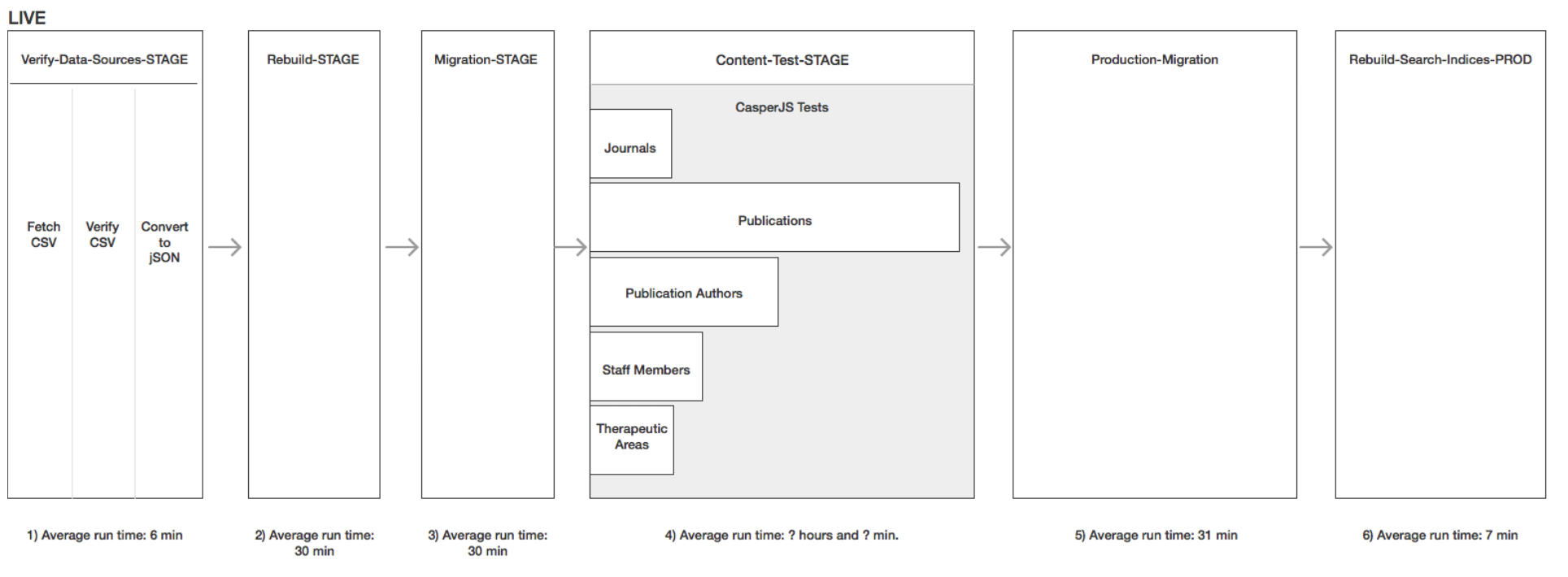
Of all of the jobs in the build process, the content tests are the longest by far (~4 hours). The content tests are run via a series of individual web requests from the Jenkins server to the web server. The tests are broken up by content type and are invoked with a shell command. The tests run for every piece of content in the migration which amounts to thousands of requests.
Most of the time spent during the job was made up of either Jenkins waiting for a response or the web server waiting for a new request. It was clear that running the content tests in parallel would take a big chuck out of the total processing time.
I looked into several options for running Jenkins jobs in parallel. At the time, the best choice was the Build Flow plugin. I broke each individual content test invocation out into separate jobs and then created a single Build Flow job to tie them together with this definition:
With this configuration and 4 executors running on the master node the content test process was bounded only by the longest individual test, publications.
This resulted in a roughly 30% decrease in total build time.
Cleanup
To round out the project, I spent some time going through the build process code and making sure that the system was outputting clear error messages at all failure points. Most of these changes were made based on actual errors we had encountered. The most common culprits were lower-level connection errors where the actual message was swallowed up and only a generic FAILURE was written to the log.
Finally
I completed the rebuild in June of 2015. These changes had a big impact on the project and opened the doors for us to make more aggressive improvements to the build. It brought stability and predictability to a process that was typically fragile and finicky. We reduced the number of non-content related build failures from weekly to almost never. When we do encounter problems we have good data and logs for troubleshooting.
Next steps
We didn’t stop there. In 2016, Jenkins gained native support for scriptable workflows via the Pipeline plugin. Next time, I will detail how we took our entire process and converted it to a Groovy-based Jenkins Pipeline.